
Using generative AI models like ChatGPT and Gemini in work has become the norm in recent days. And many human resources professionals have reverted to the widely available tools to increase efficiency. Some common use cases of generative AI in recruitment are in job ad creation, CV screening, interview question creation, etc.
However, there’s a darker side to it. For some time being, Generative AI or LLM models have been reported as biased. The problem is generative AI models are trained using biased data. For this reason, these models are prone to responding in a biased way. And these biases can be anywhere from gender bias to confirmation bias.
The thing is, with the recent developments in generative AI models, how much is the possibility that these models are still biased? If so, then how biased are these and how to bypass the biasness in these models?
According to our study of 1,439 job ads, GPT-4 generated job advertisements were on average, 29.3% more biased than human-written job ads.
ChatGPT Uses More Biased Words than Humans While Creating Job Ads
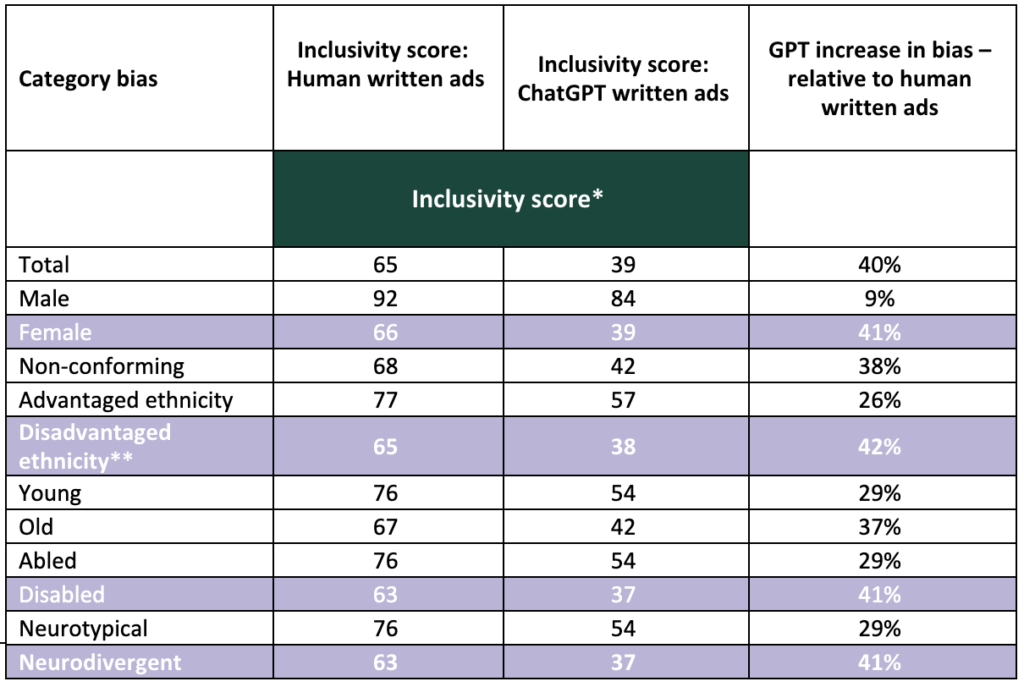
This study is a continuation of our study from February 2023. That study reported that, ChatGPT generated 40% more biased text while making job ads compared to humans. Here are the results from the study of last year –
However, this year, we saw the revolutionary GPT 4o model. Curious by its capacity, we at Develop Diverse decided to update the study. Primarily we ran a small-scale study to see if it was different and back then we shared the results through our newsletter.
Subscribe to our newsletter and get the latest insights delivered to your inbox
How did we conduct the study?
We accumulated publicly available job adverts from the internet. Next, we tokenized the job adverts to filter the job titles, companies, industries, etc. details that would help us generate the prompt. At the same time, we ran job adverts through our platform to get their detailed inclusivity scores.
Next our linguist Linea Almgren, instructed GPT 4 to make it understand the concept of diversity, equity and inclusion and prompted it to create inclusive job ads. After this, we made the same titled job adverts using the prompt of Linea with GPT 4.
Finally, we ran the GPT 4 generated job ads through our platform and compared the score with the human written ones. Here we are using our platform to understand the inclusivity of the text generated because our platform has scientific base for its credibility.
Here’s a snapshot from our platform –

Our platform analyzes text based on different categories of bias and assigns scores based on percieved level of bias. In other words, our software can detect what words and phrases affect specific groups. In the snapshot, the sample text is given an inclusivity score of 49 (we recommend to be above 90) and in the ‘Older’ category it gets 48.
How Biased are GPT 4 Generated Job Ads?
Based on the 1439 job ads we analyzed, we can say that, GPT 4 generates 29.3% more biased job ads. The average of Overall Inclusivity Score of GPT 4 written job ads was 40.9 and for human written job ads it was 57.9 (the higher the score the better it is).
To understand the bias in GPT-4 generated job advertisements compared to human-written ones, let’s examine the following table:
| Score Type | GPT-4 Average | Real Average | % Increase in Bias |
|---|---|---|---|
| abled | 68.11 | 76.38 | 10.83 |
| advantaged | 68.13 | 76.64 | 11.09 |
| disabled | 42.47 | 56.67 | 25.05 |
| disadvantaged | 46.44 | 60.68 | 23.47 |
| female | 48.06 | 61.26 | 21.55 |
| male | 88.35 | 93.72 | 5.73 |
| neurodivergent | 42.72 | 57.31 | 25.47 |
| neurotypical | 68.11 | 76.38 | 10.83 |
| non_conforming | 53.68 | 66.24 | 18.96 |
| older | 47.06 | 61.33 | 23.27 |
| younger | 68.11 | 76.38 | 10.83 |
| overall | 40.88 | 57.84 | 29.33 |
How to Read the Table:
- Score Type: This column lists various categories of potential bias in job ads. ‘Overall’ indicates towards the overall inclusivity score given by the Develop Diverse platform.
- GPT-4 Average: Shows the average inclusivity score for GPT-4 generated ads in each category. Higher scores indicate better inclusivity.
- Real Average: Displays the average inclusivity score for human-written ads. Again, higher is better.
- % Increase in Bias: Indicates how much more biased GPT-4 ads are compared to human-written ones. A positive percentage means GPT-4 ads are more biased in that category.
Key Findings:
1. Overall Bias:
GPT-4 generated job ads are 29.3% more biased overall than human-written ones, with an average score of 40.9 compared to 57.8 for human-written ads. This significant difference suggests that while AI has made strides in generating coherent job descriptions, it still lags behind humans in terms of creating inclusive content.
2. Consistent Bias Increase:
GPT-4 shows increased bias across all categories, ranging from 5.7% to 25.5%. This consistency is noteworthy as it indicates a systematic issue rather than isolated problems in specific areas. However, we cannot take all the bias increase for GPT 4 negatively. For example, having a really high inclusivity score towards ‘male’ category means preference towards men. So, GPT 4 having a lower score in this category compared to humans, is actually a good thing here.
But that doesn’t mean we should ignore the prominent proof of AI gender bias in hiring. In fact, the gap between ‘female’ and ‘male’ score for GPT4 is much bigger (40) compared to human written ads (32) – therefore it has higher gender bias.
3. Most Biased Categories:
Both GPT-4 and human-written ads struggle most with inclusivity for disabled and neurodivergent candidates, showing the lowest scores in these categories. For GPT-4, the scores are 42.5 for disabled and 42.7 for neurodivergent candidates, compared to 56.7 and 57.3 respectively for human-written ads. Simply put, from the table we can see that physically disabled and neurodivergent people are excluded the most. This highlights a broader societal issue in addressing the needs of these groups and stereotypes towards them in the workplace, which is then reflected and amplified in AI-generated content.
4. Least Biased Category:
Both types of ads show the highest inclusivity scores for male candidates (88.4 for GPT-4, 93.7 for humans), suggesting a general bias towards male-oriented language in job advertisements. This finding is particularly interesting as it reveals an ingrained preference for terms or attributes we connect to masculinity in professional contexts, which the AI model has likely learned from its training data.
5. Largest Disparities:
The categories with the biggest increase in bias for GPT-4 are neurodivergent (25.5%), disabled (25.0%), and older candidates (23.3%). These substantial differences indicate that GPT-4 is particularly struggling to generate inclusive language for these groups. This could be due to a lack of representation in the AI’s training data or a reflection of deeper societal biases against these groups in professional settings. This is a great barrier towards creating a neurodivergent workplace.
6. Consistent Patterns:
Despite the increased bias, GPT-4 generally mirrors the pattern of inclusivity scores seen in human-written ads. This suggests that the AI is accurately capturing the existing biases in human-written job advertisements but is amplifying them in its outputs. So, in some cases this is good and in some cases this is bad. For example, both human and AI-generated ads show higher scores for “advantaged” compared to “disadvantaged” candidates, but the disparity is more pronounced in GPT-4’s output.
This means that human written job ads have a higher preference for advantaged category but also for disadvantaged category. But GPT 4 written job ads have a lower preference compared to human written ones when it comes to both ‘advantaged’ and ‘disadvantaged’ categories.
These findings underscore the complexity of bias in AI-generated content and highlight the need for targeted improvements in AI models, especially in areas related to diversity and inclusion and recruitment. They also emphasize the importance of using AI as a tool to augment human judgment rather than replace it entirely in sensitive areas like job advertising.
How Much Has the GPT Improved?
The new study shows a significant reduction in bias in ChatGPT across most categories for GPT-4 generated job ads compared to the previous study. Overall, the increase in bias dropped from 40% to 29.3%, with notable improvements in inclusivity for females, disadvantaged ethnicities, and neurodivergent individuals. However, it’s wrong to say that GPT4 has become less biased over time.
We have 2 points to consider here –
- Human Scores Declining: Comparing the two studies, human-written ads show a noticeable decrease in inclusivity scores across most categories.
- GPT-4 Scores Improving: GPT-4’s scores have generally improved or remained similar between studies. The overall score increased slightly from 39 to 40.9.
Reflecting on this, our Data Science Student, Mark explained that, “We can actually see this by comparing the table from last year to the new table. The drop in inclusivity in the human-written ads from last year to this year (65 to 58) is greater than the improvement in inclusivity in the GPT4 ads from last year to this year (39 to 40).”
This indicates that the apparent improvement in GPT-4’s performance is largely due to the decline in human-written ad scores, rather than a dramatic increase in GPT-4’s capabilities.
Which Generative AI model is Most Inclusive?
We also conducted a small-scale study with the 3 latest generative AI models out there. The GPT 4o, Gemini 1.5, and Claude 3.5 Sonnet were put up to the test in our Develop Diverse platform.
We asked the 3 models to create inclusive job adverts for our chosen company and position. But before asking the models to do that, we tried to teach those what inclusive job ads are. So, once the job ads were made, we ran all those through our platform and noted the overall inclusivity score for each of the job ads.
To get a clear picture we chose companies and positions across different industries and different hierarchy levels.
So, among GPT 4o, Gemini 1.5 and Claude 3.5 Sonnet, which generative AI model is more inclusive?
Based on our study we found that Claude 3.5 Sonnet is more inclusive than GPT 4o which is more inclusive than Gemini 1.5. Here’s the test results in a table –
| Sector | Position | Country | ChatGPT 4o Score | Gemini Score | Claude 3.5 Sonnet Score |
|---|---|---|---|---|---|
| Finance | Finance Reporting Manager | Mexico | 46 | 35 | 67 |
| Retail | Store Manager | Denmark | 28 | 19 | 36 |
| Tech | Senior Software Engineer | USA | 54 | 27 | 61 |
| Offshore Energy | Deck Electrician | Offshore | 60 | 47 | 49 |
| Journalism | Senior Editor | UK | 35 | 25 | 58 |
| Travel and Leisure | Junior Product Designer | Remote | 53 | 25 | 62 |
| Healthcare | Medical Assistant | USA | 60 | 26 | 62 |
| Automotive | Maintenance Mechanic | Germany | 38 | 38 | 53 |
| Education | History Teacher | Ireland | 38 | 31 | 39 |
| Security | Regional Security Officer | Qatar | 49 | 49 | 62 |
| Average | 46.1 | 32.2 | 54.9 |
Now, let’s analyze the results –
Analysis of Results:
As we said earlier, according to the test, Gemini 1.5 is the most biased compared to the GPT 4o and Claude 3.5 Sonnet. Let’s diver deeper into the results –
1. Overall Performance:
Claude 3.5 Sonnet achieved the highest average inclusivity score of 54.9. GPT-4o came in second with an average score of 46.1, 16% lower than Claude. Gemini 1.5 had the lowest average score of 32.2, 41% lower than Claude and 30% lower than GPT-4o.
These scores indicate that while AI has made progress in generating inclusive content, there’s still substantial room for improvement across all models. For users considering these tools, it’s crucial to understand that even the best-performing model (Claude 3.5 Sonnet) is achieving only about 55% of the potential inclusivity in job ads.
2. Consistency:
Claude 3.5 Sonnet consistently outperformed the other models, scoring highest in 8 out of 10 scenarios. GPT-4o generally scored second-highest, with Gemini 1.5 typically scoring the lowest. There were two exceptions: the Offshore Energy and Security positions, where GPT-4o or Gemini 1.5 scored similarly to or higher than Claude 3.5 Sonnet.
This consistency suggests that Claude 3.5 Sonnet may be more reliable for users seeking to create inclusive job advertisements across various industries and positions. However, the exceptions highlight that no model is perfect across all scenarios.
3. Industry and Position Variations:
All models showed variability across different industries and positions. The Finance Reporting Manager position in Mexico saw the highest score disparity between models (Claude: 67, GPT-4o: 46, Gemini: 35). The Maintenance Mechanic position in Germany showed the closest scores between GPT-4o and Gemini (both 38).
These variations underscore the importance of human oversight in the job ad creation process. Users should be aware that AI performance can vary significantly depending on the specific industry or role, and should not rely solely on AI-generated content without review.
4. Geographical Insights:
The models’ performance varied across different countries and regions. Remote positions (e.g., Junior Product Designer) showed significant differences between models, suggesting that location-independent roles still present challenges for inclusive language.
For organizations creating job ads for various locations or remote positions, this variability highlights the need for careful consideration of regional and cultural factors that AI models might not fully capture.
5. Hierarchy Levels:
The models’ performance didn’t show a clear pattern based on job hierarchy (junior vs. senior positions). This suggests that the level of inclusivity is more dependent on the specific role and industry rather than the seniority of the position.
What Does This Mean for Job Ad Creation?
It’s important to recognize that while these AI tools can be helpful in generating initial drafts, they should not be relied upon as the sole means of creating inclusive job advertisements. Even the best-performing model, Claude 3.5 Sonnet, achieves an average inclusivity score of only 54.9 out of 100, indicating that nearly half of the potential for inclusivity is still missing.
The significant performance gap between models (Claude 3.5 Sonnet scoring 70.5% higher than Gemini 1.5 on average) emphasizes the importance of tool selection. Organizations committed to diversity and inclusion in their hiring practices may want to prioritize using more inclusive models like Claude 3.5 Sonnet. However, they should remain aware that even this leading model has limitations.
Given the variability in scores across different sectors and positions (ranging from lows of 19-28 to highs of 60-67), users should be particularly vigilant when creating ads for certain industries or roles where AI models tend to perform poorly in terms of inclusivity.
Final Thoughts
Our studies have revealed significant challenges in AI-generated job ads. While GPT-4 showed increased bias compared to human-written ads, our comparison of leading AI models found Claude 3.5 Sonnet to be the most inclusive, though still far from perfect.
These findings underscore that AI, while valuable, should not be used in isolation for creating job ads. Human expertise remains crucial in ensuring inclusivity. As AI evolves, we can expect improvements, but a balanced approach combining AI assistance with human judgment is currently essential. Long story short, trusting AI blindly in generating job ads doesn’t quite fall under the best practice of writing inclusive job ads.
To address these challenges and create truly inclusive job advertisements, tools like Develop Diverse can play a crucial role. Our platform helps identify and eliminate bias in job ads, whether human-written or AI-generated. By leveraging such tools and maintaining a commitment to inclusivity, we can work towards a more equitable and diverse job market for all.



